
导读:淘宝每天都会产生海量的评论。消费者在购买商品的时候希望通过评论来了解其他用户对该商品的看法,但是他们很难去浏览全部评论。所以如何高效地帮助用户去理解其他用户对商品的观点是一个需要解决的问题。我们可以对用户产生的UGC内容(User Generated Content)做情感理解,并基于评论中对商品属性的情感倾向,结合情感知识以及用户个性化观点推荐,进行汇总并展示。今天和大家分享一下淘宝业务场景下针对UGC情感计算的解决方案和应用,主要包括以下几方面内容:
- UGC情感计算背景介绍
- 情感分析挖掘流程
- 观点抽取模型
- 融入情感知识的预训练模型
- 印象词个性化排序
- 业务应用案例
- 未来工作
01
UGC情感计算背景介绍
首先和大家分享下UGC情感计算在淘宝的应用背景。
1. UGC情感计算在淘宝APP的应用场景
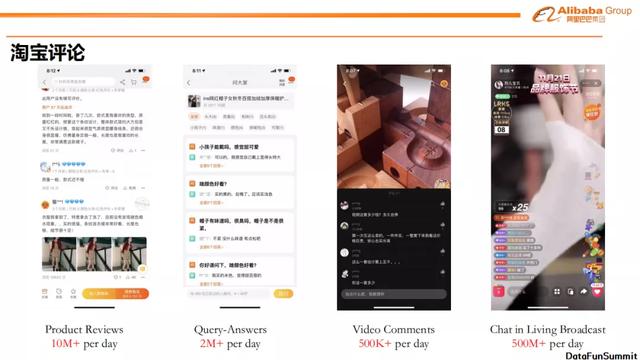

在淘宝APP中,UGC的来源非常广泛,大家在购买商品时会看到其他用户对商品的评论,每天新增的评论数可以达到千万级别。
淘宝APP的短视频业务场景下会产生百万级别的评论,而直播间的评论规模会更加巨大。
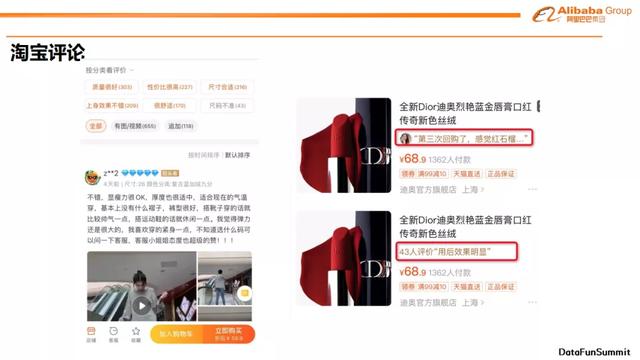
此外,当用户进入一些搜索场景时,我们可以展示出用户对目标商品的观点。例如我们正在搜索“口红”这一品类的商品,这时我们会推出一些已经购买过该商品的用户发表的观点或者他的使用感受。除此之外,我们也会通过展示一个汇总型观点来帮助用户了解大部分购买过该商品的用户对商品的态度,并通过它们促使用户更好地去做购物的决策,更快速地去了解这个商品的优缺点。通常,我们需要对UGC做下面三个事情:商品属性词提取,情感词提取和情感词情感极性分析。
下面,我们对UGC情感计算任务做一个定义。
2. UGC情感计算任务的定义

我们先来讲讲什么是属性。属性可以被定义为商品的一个部件或者一个部分。比如说笔记本的电池,其本身是笔记本的一个部件,也是它的一个部分,所以我们可以把它定义为一个属性。商品本身也存在一些固有属性,比如商品的价格,材质等。属性还可以是商品的一个组件或者某一部分的一个属性,例如笔记本电池的寿命。
我们还需要抽取出评论中存在的情感词。情感词是用户对一个属性表达主观情感倾向的一些词语,例如评论中用户描述笔记本电池的寿命长,句子表达的是用户电池寿命的正向情感,情感词是“长”,解释了情感倾向的原因。
对于用户情感倾向的分析任务对应着判断用户对属性输出情感词的词性。在情感计算任务中,我们更多地关注情感的正向、负向和中性这三类。
比如在服饰类商品的评论中,用户表示“收到货感觉布料不错,试穿一下很好,就是拉锁不太好拉,穿上很舒服,效果也很好,值得购买”,那么按照<属性词,情感词,情感属性>这三部分,我们可以分析出<布料,不错,正向>这一三元组。因为布料是服饰的一部分,而情感词对应着“不错”,其情感倾向显然是正向的。而对于“试穿一下很好”,句子中仅包含了情感词“很好”,那么它描述的是试穿的效果,那么试穿效果就是一个隐含属性,对应的情感倾向应该是正向的。还有后面用户描述“拉锁不太好拉”,它对应的是服饰的一个组成部分,情感词“不太好拉”很明显表达了比较负面,或者是贬义的一些情感倾向,所以它是一个负向的情感极性。然后“穿上很舒服”,“穿上”是服饰的一个上身效果,它是对应的一个属性,其对应的情感词是“很舒服”,是一个正向的情感倾向。然后“效果”也是服饰的一个属性,情感词对应的是“也很好”。对于情感词“值得购买”的话,它描述的是是否要回购,是服饰的回购属性,“值得”作为情感词表达的是一个正向的情感倾向。
3. UGC情感计算面临的问题&挑战
针对UGC情感计算任务,我们面对的挑战很大一方面来自于业务本身的特性。
- 首先,品类不同,领域的属性与表达情感的方式存在巨大差异,即包含长尾case。比如味道对于食品而言是一个属性,但对于烹饪用具而言并不是其商品的属性。
- 此外,对于同一个情感词,在不同品类或者领域下情感倾向会有很大的不同。例如,“很干”对于蒜和对于水果所表达的情感倾向完全相反。
- 很多用户评价观点的表述所包含的内容十分丰富,领域的差异和相同表达在不同领域标注数据量的比例不同会对有监督模型的泛化能力提出很大的挑战。
- 另外对于淘宝这一商业场景会存在一些负向评论,但是其在整体数据下的占比比较少,在不同领域里可能会达到10:1或者20:1。标注这些极端情况的样本较为困难,且数据不均衡会导致部分负向样本分类准确率非常低。
- 最后,跨领域问题也是一个较大的挑战。比如“声音小”对冰箱来说是正向情感,而对于音响来说是一个负向的倾向。
02
情感分析挖掘流程
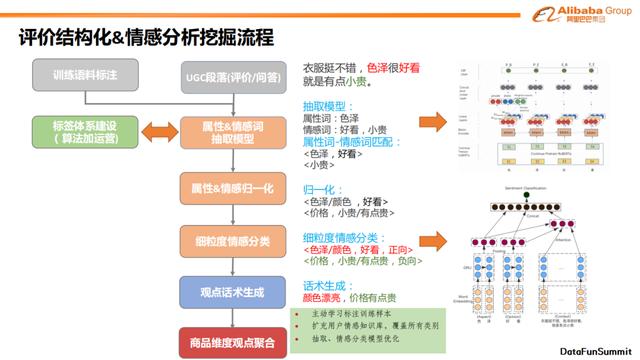
下面先总体介绍一下我们设计的UGC情感分析系统。我们选择了有监督的训练方式,因为无监督无法达到我们所需要上线的性能要求。我们会把UGC段落一起送入属性&情感词抽取模型。UGC片段可能来源于用户对于商品的评论、用户在直播间的评论、用户在短视频的评论,问答区等。
之后,抽取模型会将它们拆解成(属性,情感词,情感极性)三元组的形式。首先抽取模型会分别抽取属性以及情感词。之后进行一个匹配任务,即哪一个属性对应哪一个情感词。UGC中可能存在独立的情感词,代表其描述的是一个隐含属性。此外,经过属性的情感抽取后,我们会得到较多的属性-情感词对,但表达相同属性和情感的配对分布在不同用户的评论中,我们需要把这些相同语义的属性-情感对使用同一个观点进行描述,并在最后方便进行观点的汇总和展示。基于以上理由,我们需要对属性&情感进行归一化。具体地,归一化会对之前生成的属性-情感对进行隐含属性的补全,并将相同属性或者语义相同的情感词进行聚类。在归一化之后,我们会有一个分类模型,对属性-情感对进行情感倾向的识别。
在线上展示时,我们会使用一个观点生成模块和一个观点聚合模块。其作用就是在商品维度下,对表达相同观点的话术进行汇总,生成一个统一的观点进行展示。当然,在整个系统中,我们会通过主动学习不断地把模型中表现不好的样本挖掘出来进行人工送标,然后不断地去提升模型的效果。
03
观点抽取模型
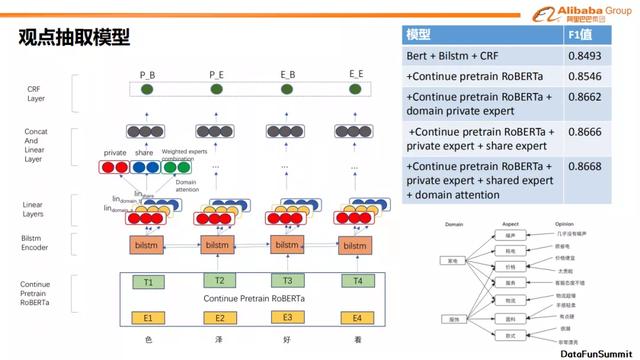
下面详细讲解观点抽取模型。模型的输入为一条评论,模型backbone基于RoBERTa。使用电商评论对RoBERTa进行持续训练,使得模型能在特定domain下得到更好的表达。RoBERTa之后会经过一个BiLSTM层,目的是为了获得一个更加抽象的序列特征。中间Linear层的设计初衷是为了使模型能更关注当前领域的特征,因为领域特有的属性、情感极性等在淘宝场景下非常普遍且使用传统方法难以获取。比如同样一个词语在不同领域下面有可能是属性词,有可能不是属性词,所以为了更好地去刻画这类词语,我们需要一个专家网络去控制词语在某一领域下的特征。我们的做法借鉴了MMOE,并且在此基础上加入了领域共有(shared)的属性。比如在电商这个场景,商品的价格、商家的服务、物流的快慢等。加入共有属性的优点是对于一些领域中标注稀少的属性,如果在别的领域标注较为充足,那么这一领域可以很好的利用共有属性来表达它们的特征。此外,我们还加入了动态共享的特征,采用attention机制,使得模型在当前领域下具有特征筛选的能力。最后,三种特征拼接在一起,经过特征映射和CRF层,解决标签连续性问题,得到最后的输出。
经过大量实验,我们得到在Bert+BiLSTM+CRF的基础模型下F1值为0.8493,将backbone替换为持续学习机制的RoBERTa后F1值提升至0.8546,加入领域私有专家网络后F1值进一步提升至0.8662,加入领域共有网络后F1值继续提升至0.8666,最终加入attention机制的模型F1值可以达到0.8668。当然,在线下实验中数据规模较小,真实模型在线上实验时,我们对case进行了抽样,发现加入上述优化后表现提升更为明显。
04
融入情感知识的预训练模型
使用融入情感知识的预训练模型的原因是抽取任务和属性级情感分类任务都是直接依赖和情感表达相关的知识(如属性、情感词),在预训练获得这方面的通用知识对下游任务的提升会比较直接。如果我们完全依赖标注数据去训练模型,受限于高昂的标注成本,我们所拥有的(属性,情感词,情感倾向)的三元组训练样本规模较小,且存在长尾表达,使得模型拟合效果较差。
我们预训练中所使用到的知识类别有情感通用知识和电商领域特有知识。情感通用知识有情感词,词性,词级别的情感极性,对情感极性产生逆转的否定词,表达情感强烈程度的程度副词,形容词等。这些知识的获取方式可以为开源以及日常业务相关的情感词库或者POSTAG。而对于电商领域特有知识则包含商品属性,商品情感词,商品属性-情感词搭配,商品名(实体)。此外,我们还加入了上下文相关的知识,例如商品所属的类目,品类,商品的CPV/CTV体系,商品标题等。这类知识需要无监督挖掘或者现有模型进行直接挖掘来获得。
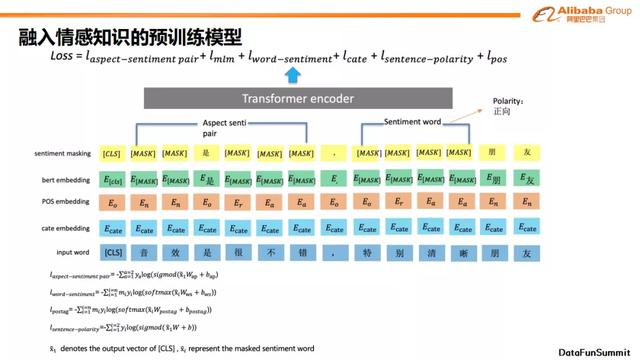
目前我们的模型融入情感知识的方式是通过加入知识相关的embedding和情感词级别的mask,使得模型经过预训练能更加关注我们加入的知识信息,从而对下游任务有一个明显的提升。
具体地,在bert传统的embedding的基础上我们加入了category embedding,并通过sentiment masking实现情感词知识的融入。其中sentiment masking的思路与bert类似,我们希望模型可以通过恢复属性-情感词配对或者情感词来获得情感词知识的表达。此外,用户对于一个商品其实存在一个总体的情感倾向,这对于判断属性的情感倾向非常有帮助。所以,我们把句子的总体情感极性加入到预训练的目标函数。最终,我们的模型的损失函数由六部分组成,分别对应着属性-情感词对的预测损失,Bert传统的预训练任务的损失函数,情感词的预测损失,商品品类的预测损失,句子整体情感极性的预测损失以及POSTAG任务的损失函数。
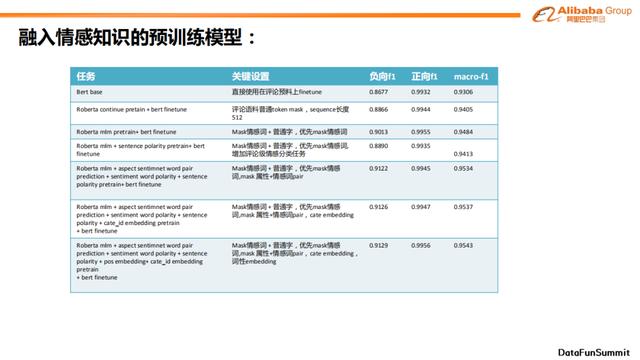
经过实验,我们发现通过逐步加入之前所提出的trick,得到的F1值在大部分情况下都有提升。Bert基模型的macro-f1值为0.9306,而加入所有embedding和masking技巧后,模型最终的macro-f1值可以达到0.9543。
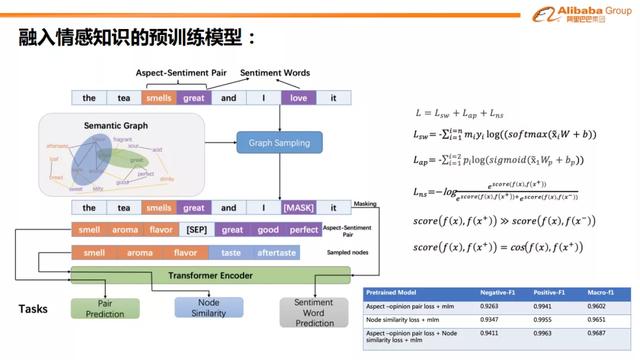
我们在预训练模型的基础上还尝试加入了情感图谱。构图的想法来源于预训练模型对于领域内某些长尾case效果不佳,而加入图谱可以使这些长尾case能匹配到一些相似的表达。这些长尾样本可能在当前领域标注不足,而在其他领域有充分的样本标注,这时通过建图的方式可以使它们获得更好的表达。这一做法也可以近似看作为数据增强。
情感图谱的构建过程如下所述。首先,我们会去挖掘一些表达相似的观点,相似的属性以及相似的情感词。挖掘的过程可以通过有监督或者无监督的方式并行地去完成。我们可以利用公开的语料资源,从当前目标词出发游走到相似的词语,之后通过如word2vec等静态词向量以及KNN的方式把相似的词语捞回来。当然,我们自身也会去根据自己标注的语料去训练一些模型,并且使用这些模型得到目标词的不同表达,之后经过相似度比较对候选词语进行初筛、汇总,得到目标词的相似词语。挖掘任务完成之后,我们会进行情感图谱的建立。图中的边代表着词语之间具有相似关系,而且这里的边表达的是一个意图。同时,我们会通过有监督或者规则的方式去挖掘属性-情感词的pair。如果属性节点和情感词节点可以组成一个pair,那么我们也会在图中给这两个节点加上一条边。综上所述,我们可以构建出一个较大的情感语义图。
在模型预训练的过程中,对于一条输入评论,我们首先通过构建好的情感语义图以及语料中所包含的所有属性,情感词,采用随机游走或者随机采样的方式把它们的相似节点找到,得到它们的增强表达。加入情感图的模型预训练基于RoBERTa骨干网络,并且最终分为三个子任务,其中Bert最核心的原始预训练任务必须被保留。此外,我们还加入了对属性-情感词对的预测任务以及图节点相似度的预测任务。属性-情感词对的预测任务是一个二分类任务,用来预测一组相似属性以及一组相似情感词是否可以组成一个情感对。而对于节点相似性预测任务,我们可以使用类似于对比学习中NCE作为损失函数。
通过实验我们发现模型在经过情感图谱的知识增强后,对于一些长尾表达的分类效果有很明显的提升。特别的,对于数据量较少的负向表达,之前模型的F1值可能最多只有0.91,而加入情感图谱后F1值至少可以达到0.93。这可以证明通过我们这个方法可以使得模型变得更加鲁棒。
05
印象词个性化排序
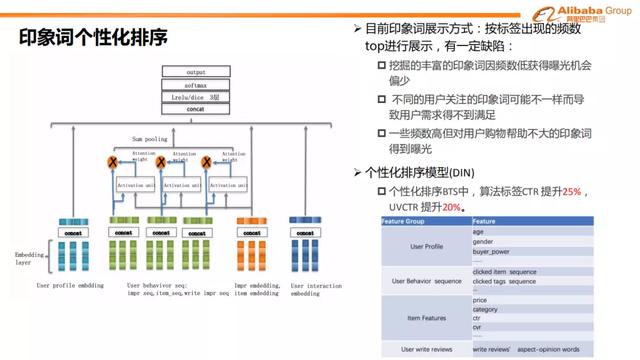
在线上话术展示时我们还会遇到展示机制本身存在的缺陷。目前印象词的展示方式是按照标签出现的频数top进行展示,这就会导致挖掘得丰富的印象词因为频数低获得曝光的机会偏少,而一些频数高但对用户购物帮助不大的印象词得到了曝光。此外,不同用户关注的印象词可能不一样,现在的机制无法满足用户的个性化需求。
基于这些问题,我们采用了个性化排序模型DIN。在特征选择中,我们使用了用户的年龄、购买能力、职业信息、收入等用户个人特征,商品本身的价格、品类等作为物品特征。同时,用户对商品的交互信息隐含了用户对商品的偏好,所以我们也使用了用户交互特征作为模型的输入。此外,用户输入评论时也会加入印象词,我们可以将这些印象词捞出来作为用户的特征进行输入。
06
业务应用案例
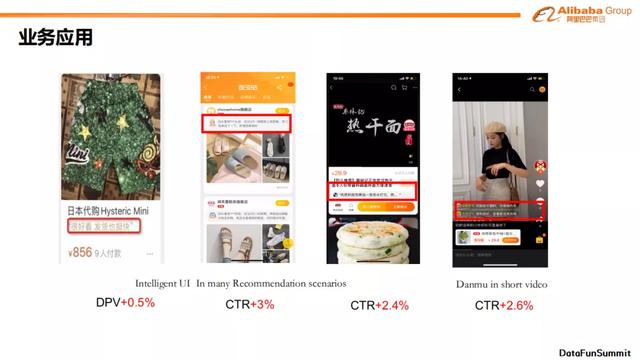
使用淘宝的同学可能也会观察到,我们会在商品标题下输出“很好看 发货也挺快”这样的评论,也会在每日好店中展示有多少回头客买了多少次这样的信息。我们在不同业务场景中会把一些比较好的观点、评论展示出来。经过线上测试,我们发现在“大家印象”中,评价标签的pctr可以增长456%,uctr可以增长250%。而在主搜模块,通过优质评价标签前置,搜索srp页透出印象词,可以使得整桶ipv增长0.55%,成交笔数增长0.31%,成交金额增长0.7%。在“首猜智能UI素材”场景中,通过在智能UI场景中投放正向情感评论,dpv增长了0.49%,pv增长了0.16%,pctr增长了2.7%。在“直通车咸鱼场景”,我们在投放淘宝商品时加入标签作为展示文案,使得ctr提升了6%。在手机淘宝mini Detail页中,我们同样通过输出正向评论可以使得PV点击率增长2.46%。在短视频业务场景中,在全屏页加入正向评论飘屏,可以让PV点击率增长2.61%,UV点击率增长0.67%。
07
未来工作
目前我们线上对某些UGC的解决效果还不是特别完美。例如,在电商场景下,用户需要我们对于负向情感判断的准确率达到100%,但由于否定case十分稀少,离达到预期效果的距离还比较大。此外,例如目前对于“香水很好,味道淡淡的,不是那种很难闻的味道”这样的复杂话术,我们的模型也无法达到很优异的效果。我们可以在finetune阶段进行规则融合、注意力改进、加入否定识别任务等进行尝试。而对于较难解决的multi entity multi aspect及转折、对比等复杂句,目前我们认为它们有一定的技术价值,但对我们业务的价值较小。
我们后续还会尝试进行端对端的<aspect, opinion word, sentiment polarity>三元组的模型训练,减少pipeline的累积误差与资源消耗。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

分享嘉宾:雍倩 阿里巴巴 高级算法工程师
编辑整理:吴祺尧
出品平台:DataFunTalk
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 sumchina520@foxmail.com 举报,一经查实,本站将立刻删除。
如若转载,请注明出处:https://www.ppcring.com/post/23692.html相关推荐
-
京东网站下载,京东网站官网下载?
出海东南亚电商市场的京东,迎来重要调整。 京东印度尼西亚电商官网(JD.ID)昨日(1月30日)发布公告称,JD.ID将从2023年2月15日起停止接受用户的订单,JD.ID及其所…
-
京东触屏版官网怎么登陆,京东触屏版官网下载?
IT之家 2 月 7 日消息,小米笔记本 12.4 「二合一」现已在小米商城、小米有品、京东商城开启预售,将在今日上午十点正式开售,首发到手价 2899 元! 这款机型搭载了高通骁…
-
淘宝上的东西都是正品吗,淘宝的东西都是正品吗_?
随着互联网的发展,越来越多的人开始在淘宝这一平台上购物,淘宝的交易额也呈现出爆发式的增长。但是,在选购淘宝产品时,我们不禁要问:淘宝上的东西都是正品吗? 事实上,淘宝平台上的商品种…
-
亚马逊全球开店官网注册条件,亚马逊全球开店官网注册是真的吗?
11月16日,欧税通&九方通逊联合主办了“亚马逊全球开店 深圳2023峰会盛典”会议活动完美收官!本次峰会盛典是2022年末一场重磅的活动,会议当天超500人出席,当天欧税…
-
投诉淘宝店铺投诉电话,投诉淘宝店铺投诉电话入口?
在如今淘宝平台充斥的假货、虚假宣传、不实评论等问题中,消费者的维权意识越来越强烈。而淘宝平台上的店铺也不可避免的出现一些问题。这时,我们该如何投诉呢? 一、投诉前的准备 在投诉前,…
-
行李箱淘宝店铺推荐(switch淘宝店铺推荐)
来源:企鹅吃喝指南 众所周知,身为美食编辑,我们每天工作的重要内容,就是逛淘宝。:) 尤其平时做小众选题时,往往能挖到很多神奇的宝藏店铺,逛起来简直比线下超市还上瘾! 有些品类的小…
-
建行杯第八届互联网创新创业大赛官网,建行杯第七届互联网创新创业大赛官网?
12月2日下午,西京学院第七届中国国际“互联网+”大学生创新创业大赛总结暨第八届大赛启动会在学校第二会议室召开。 副校长郭捷出席会议,各二级学院院长、以及教务科或教研科科长,获奖项…
-
互联网服务投诉平台官网电话,互联网服务投诉平台官网一二级问题怎么填?
“有事拨打110” 那么,你知道哪些事属于 110报警服务平台的受理范围吗? 近日,国务院办公厅有了明确要求 110是公安机关受理处置企业和群众报警、紧急求助和警务投诉的报警服务平…
-
百度云网盘搜索引擎资源下载(百度云网盘搜索引擎官网)
通常,营销人员在争夺流量时会非常关注谷歌。例如,我敢打赌,你的 SEO 会议主要围绕 Google 的主题展开,诸如“我们的自然搜索怎么样?”之类的问题。 “我们如何在 Googl…
-
淘宝逛逛怎么赚钱,淘宝创业赚钱方法?
淘宝逛逛成为淘宝平台上的重要流量来源之一,也成为商家们获取流量的新渠道。通过在逛逛上发布短视频,商家可以展示产品的真实使用体验和评价,从而吸引潜在的买家,提高转化率。因此,淘宝逛逛…